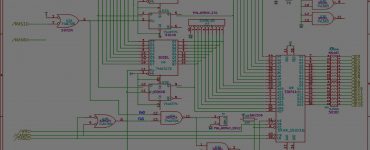
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals
Search
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals
Search
Search
Tag - sample
Amiga Floppy
Inactive
Visualizing amiga track data with matlab
2 comments
Amiga Floppy
Inactive
on recent disk reading results
4 comments
Amiga Floppy
bought a Saleae Logic. Another tool for my toolbox
1 comment
Amiga Floppy
Intronix LA1034
1 comment
Amiga Floppy
mid-january status
3 comments
Amiga Floppy
Latest attempt
Add comment
Amiga Floppy
not the PC again?
2 comments
Amiga Floppy
review of timing details
1 comment
Amiga Floppy
Changes to the PC side
1 comment
Amiga Floppy
still hashing some ideas around
3 comments
Load More
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals