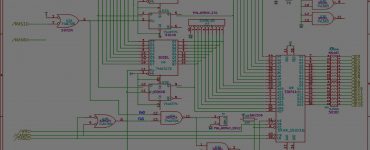
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals
Search
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals
Search
Search
Tag - sector
Amiga Floppy
Inactive
on recent disk reading results
4 comments
Amiga Floppy
Inactive
found bug last night
Add comment
Amiga Floppy
Inactive
re-examining XOR data checksum used on amiga floppies
5 comments
Amiga Floppy
Inactive
working FPGA version of the amiga floppy project
2 comments
Amiga Floppy
redone transfer routine
2 comments
Amiga Floppy
feasability of writing disks
2 comments
Amiga Floppy
first real world tests
Add comment
Amiga Floppy
intermittent problem found
1 comment
Amiga Floppy
great performance increases
2 comments
Amiga Floppy
SlackFest 2007
2 comments
Load More
Reverse Eng’ing PALs
HOPE Computer
A501 DRAM Card
Modifying C920
Amiga floppy blog pages
Download
Project Goals